Pose-conditioned Spatio-Temporal Attention
for Human Action Recognition

Fabien Baradel
INSA Lyon

Christian Wolf
INSA Lyon

Julien Mille
INSA Centre Val de Loire
arXiv:1703.10106
Abstract
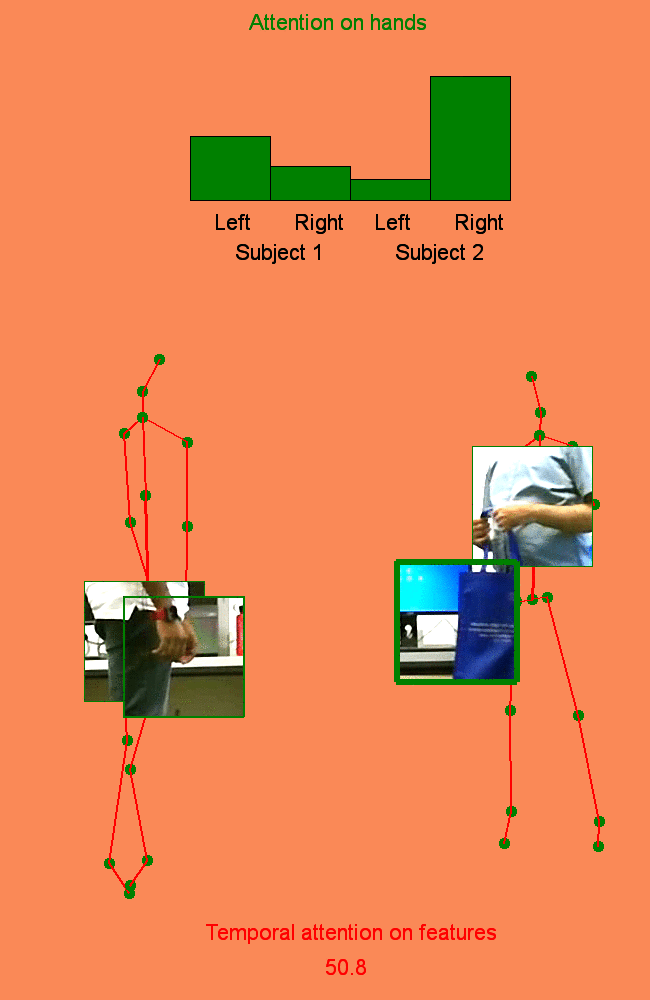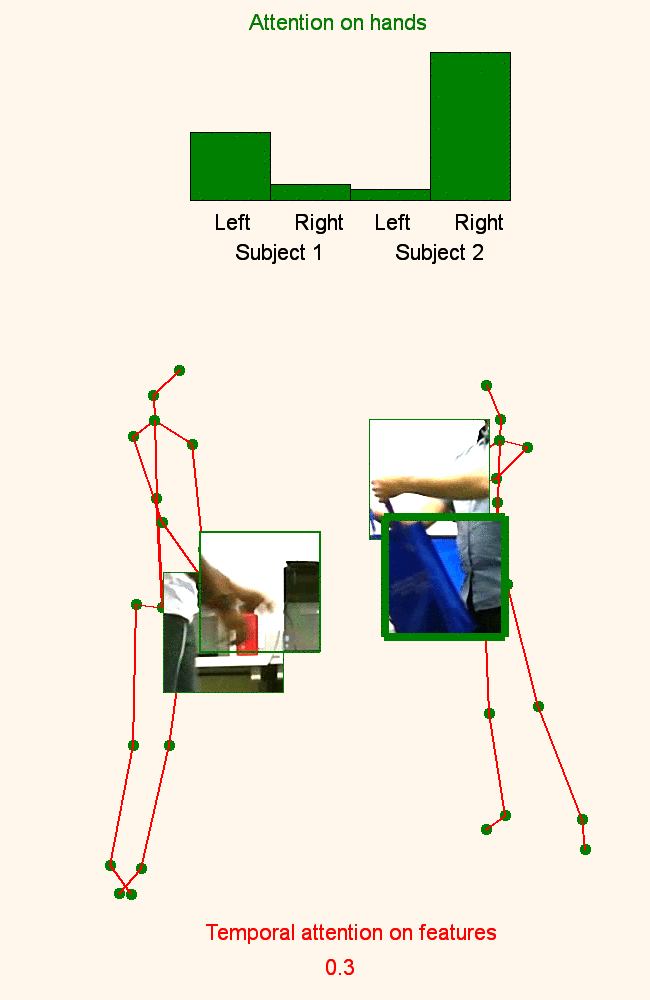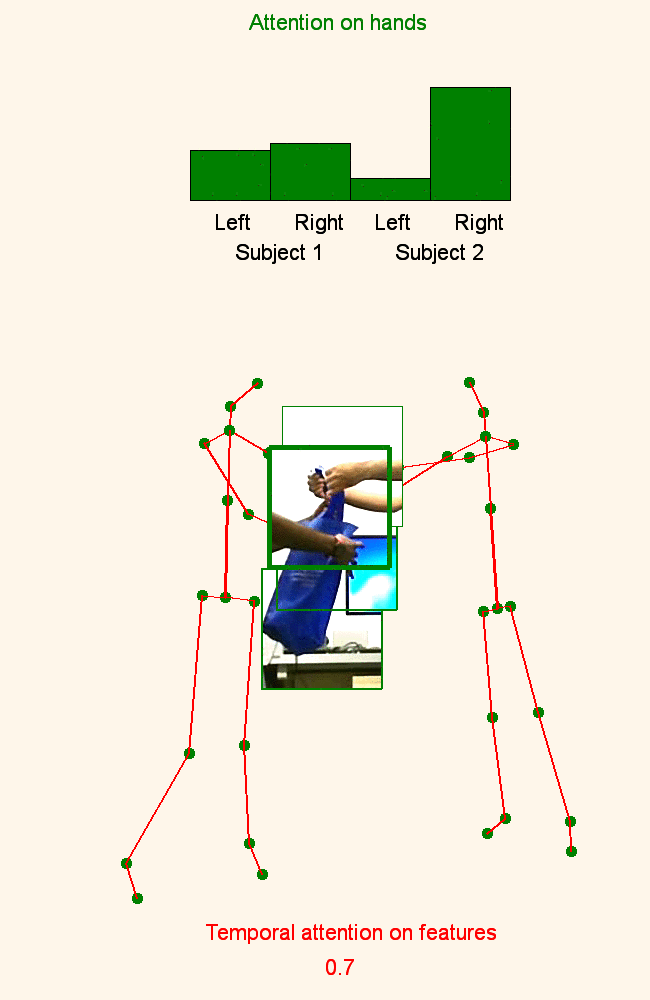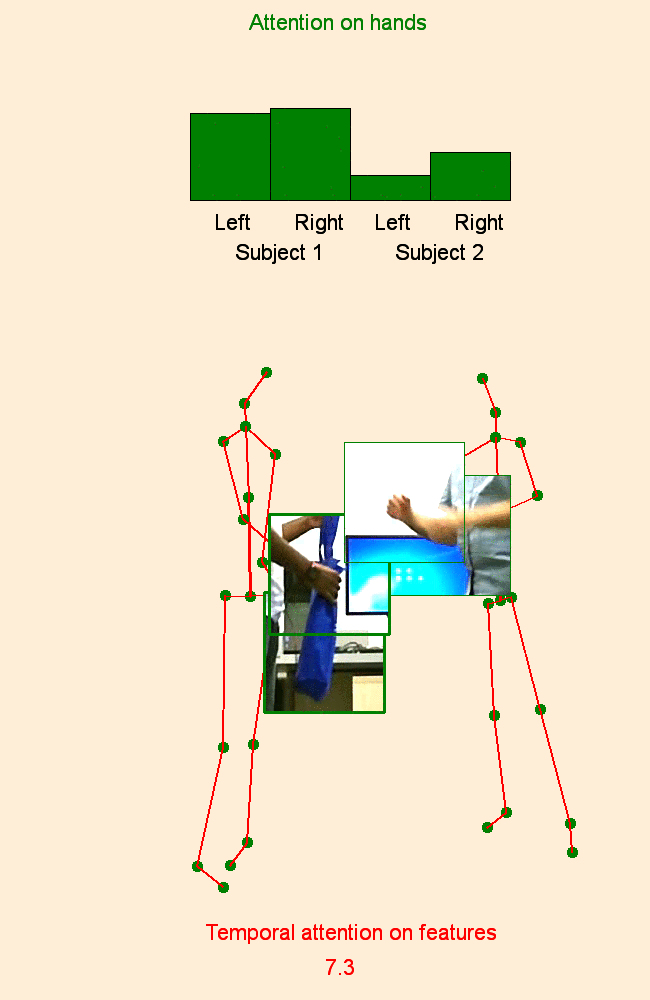
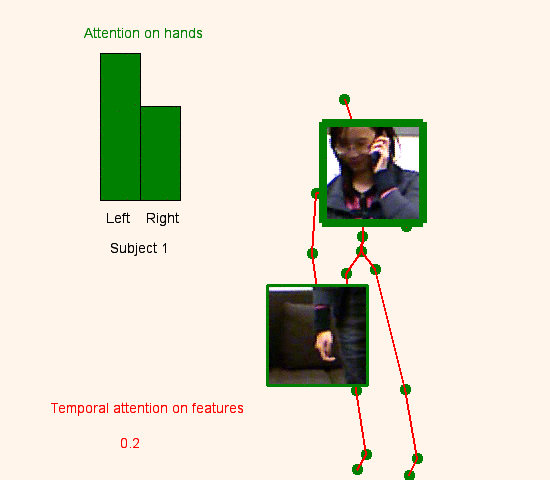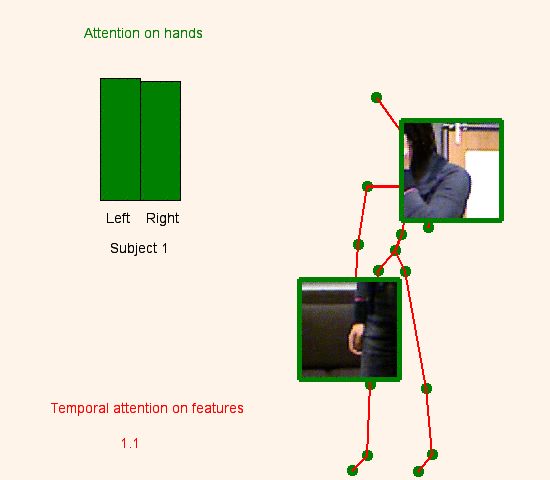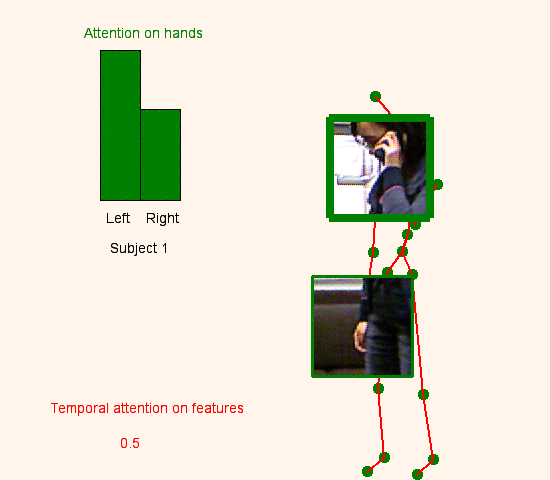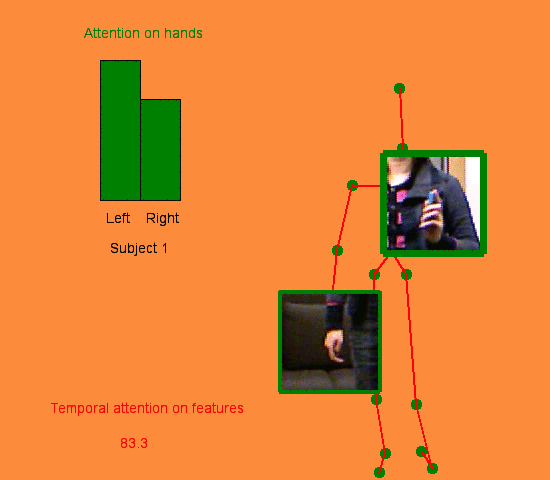
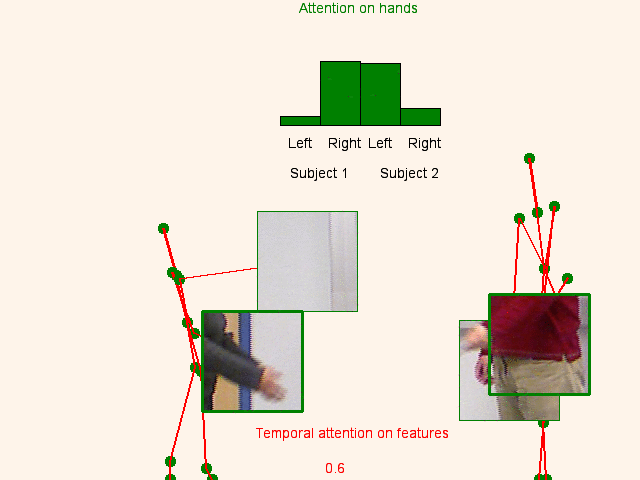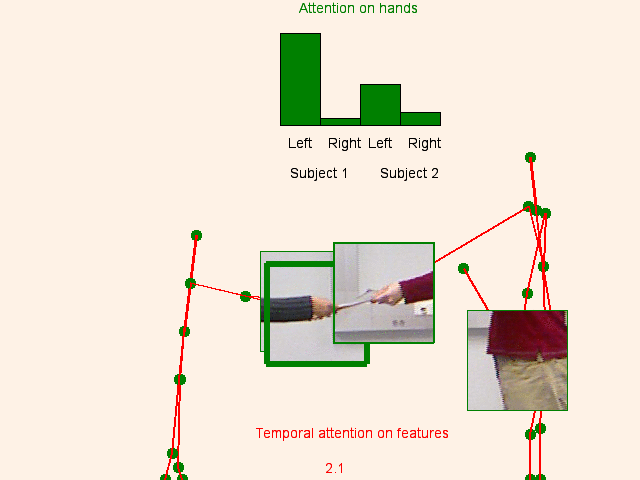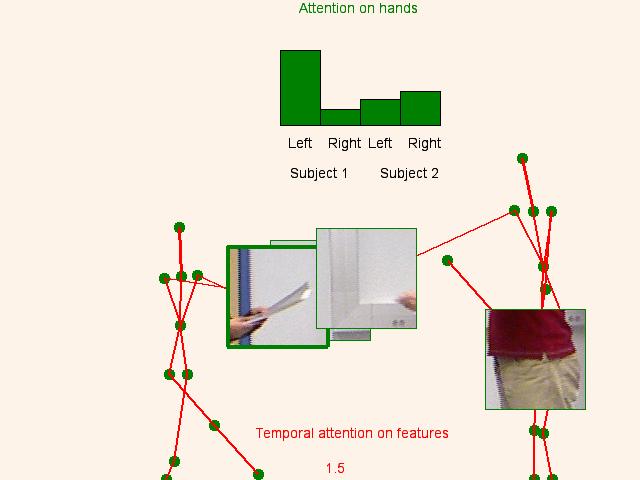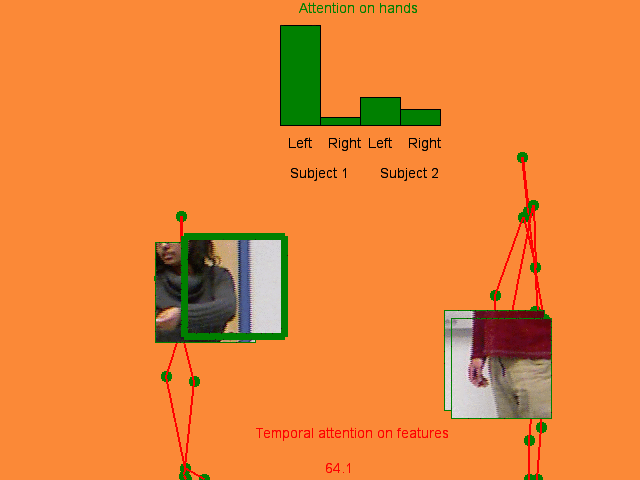
We address human action recognition from multi-modal video data involving articulated pose and RGB frames and propose a two-stream approach. The pose stream is processed with a convolutional model taking as input a 3D tensor holding data from a sub-sequence. A specific joint ordering, which respects the topology of the human body, ensures that different convolutional layers correspond to meaningful levels of abstraction. The raw RGB stream is handled by a spatio-temporal soft-attention mechanism conditioned on features from the pose network. An LSTM network receives input from a set of image locations at each instant. A trainable glimpse sensor extracts features on a set of predefined locations specified by the pose stream, namely the 4 hands of the two people involved in the activity. Appearance features give important cues on hand motion and on objects held in each hand. We show that it is of high interest to shift the attention to different hands at different time steps depending on the activity itself.Finally a temporal attention mechanism learns how to fuse LSTM features over time. We evaluate the method on 3 datasets. State-of-the-art results are achieved on the largest dataset for human activity recognition, namely NTU-RGB+D, as well as on the SBU Kinect Interaction dataset. Performance close to state-of-the-art is achieved on the smaller MSR Daily Activity 3D dataset.